LDA 하라고 하면 혼자 할 수 있겠어?
.... 아뇨
공부를 아무리 해도 내가 혼자 구현하지 못하면 프로젝트 내에서 할 수 없는 것.. 코드를 혼자서 오나전 구현시켜 볼 수 있어야 된다. 부담 오조오억배.. 되어서 죽을뻔..
그러니까 다시 한줄한줄씩 코드를 뜯어보자
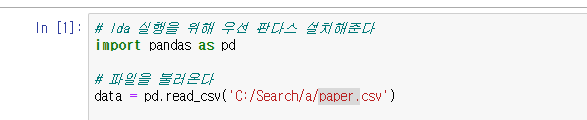
Pandas import
먼저 판다스를 임포트 해준다
파일이 안 불러 졌는데 파일경로와 파일명을 직접 적어주고 .csv 를 적어준다. (피일에는 굳이 .csv 안해도 된다)
- data = pd.read_csv)'C:/Search/a/paper.csv)
index 지정

data_text = data[['title']] 와 data['title'] 의 차이
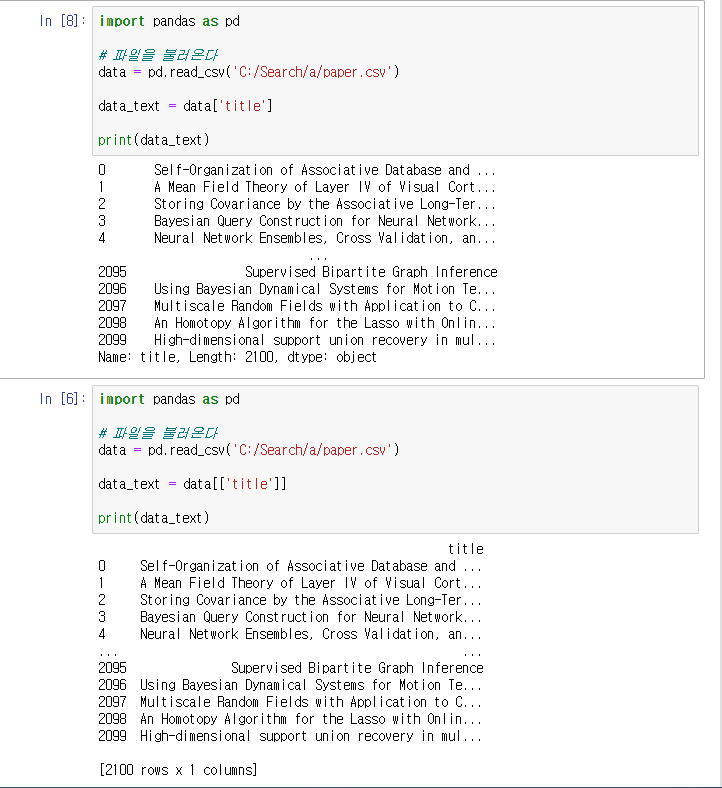
[] 리스트 하나로 해주니 타이틀 인덱스만 출력이 되긴 하였는데
우측 상단에 title 의 여부가 갈렸다.
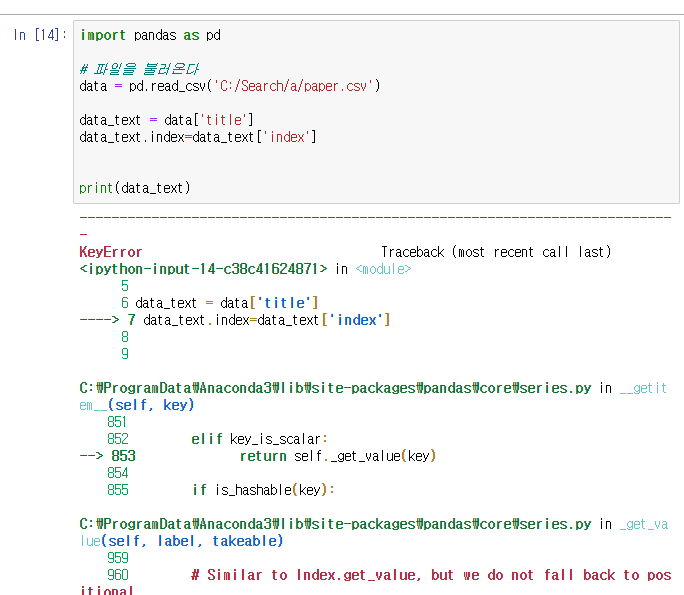
data_text['index'] = data_text.index 와 data_text.index = data_text['index'] 의 차이
[인덱스]를 설정해준다고 []를 먼저 써주고, .index 로 만들어준다
반대로 하면 인덱스 설정 불가
후에
- data_text['index'] 실행해줄 때에도 title 이 없으니깐(['title'] 인덱스 번호도 안붙네
- data_text = data[['title']] 로 데이터 컬럼을 필수적으로 저장해줘야 겠다
documents = data_text
data_text 를 보다 간결한 도큐먼트 변수에 지정한다
import nltk
자연어처리 툴키트를 임포트 해준다
* nltk 란? 자연어란 우리가 일상 생활에서 사용하는 언어
자연어처리란 컴퓨터가 자연어를 처리할 수 있도록 하는 일
자연어 처리가 되면, 처리된 정보를 바탕으로 음성 인식, 내용 요약, 번역, 감성 분석, 텍스트 분류 작업을 할 수 있다
* nltk 란? 자연어 처리를 위한 파이썬 패키지
-자연어 문서를 분석하기 위해서는 긴 문자열 분석을 위해 작은 단위로 나누어야 하는데, 이 문자열의 단위를 토큰이라고 한다
-형태소는 언어학에서 일정한 의미가 있는 가장 작은 말의 단위를 뜻하는데, 보통 자연어처리에서는 토큰으로 형태소를 이용한다
-형태소 분석이란 단어로부터 어근, 접두사, 접미사, 품사 등 다양한 언어적 속성을 파악하고 이를 이용하여 형태소를 찾아내거나 처리한다
-어간 추출은 변화된 단어의 접미사나 어미를 제거, 형태소의 기본형을 찾는 방법
-품사는 문법적인 기능이나 형태
-자연어 분석을 할 때 같은 토큰이라도 품사가 다르면 다른 토큰으로 처리한다
* 쥬피터 노트북에서 nltk 를 설치하려면 '! pip/conda install nltk' 입력해준다
import gensim
https://ebbnflow.tistory.com/153 gensim 찾다가 의미와 해석을 잘 해놓아서 첨부해놓습니다
* gensim Word2Vec 은 언어의 의미와 유사도를 고려하여 언어를 벡터로 매핑하는 방식을 사용하는 패키지임
* 토픽 모델이란? 문서집합의 추상적인 주제를 발견하기 위한 통계적 모델 중 하나로, 텍스트 본문의 숨겨진 의미구조를 발견하고자 하는 텍스트 마이닝 기법 중 하나
토픽 모델링을 해주기 위해 gensim 을 임포트 해준다.
gensim 오류는 나만의 문제가 아니니 이전 포스팅(실패 계속, 결국 선배한테 물음) 에 나와있는데 다양한 방법을 시도했으니 그대로 따라하시면 보시는 분들은 오류가 해결될 수도 있다.
import numpy as np
numpy 란? 행렬이나 일반적으로 대규모 다차원 배열을 쉽게 처리할 수 있도록 지원하는 파이썬의 라이브러리
수치계산을 용이하게 해주는 numpy 도 임포트 해준다
from nltk.stem.porter import *
from gensim.utils import simple_preprocess
from gensim.parsingd.preprocessing import STOPWORDS
from nltk.stem import WordNetLemmatizer, SnowballStemmer
stopwords 는 불용어로, 소유격, 조사,접미사, 복수형 등을 의미한다 (데이터에서 유의미한 단어 토큰만을 선별하기 위해 큰 의미가 없는 단어 토큰 제거) (I, my, me, over, ..)
stemmer 는 -es 를 잘라주고 (어간 추출)
lemmatize 는 원어를 찾아서 결과를 보여준다 (표제어 추출)

np.random.seed(2018)
( ) 괄호 안에 어떤 파라미터를 사용하든 아무 상관이 없다고 한다는데. 단지 서로 다른 seed 를 사용할 경우 numpy 로 하여금 서로 다른 유사난수를 생성하게 만든다는 점만 이해하면 된다 칸다.

stemmer = SnowballStemmer("english")
snowballstemmer 에서 사용할 언어를 지정, 약 15개의 언어가 있으며 한국어는 없다
def lemmatize_stemming(text):
return stemmer.stem(WordNetLemmatizer().lemmatize(text, pos = 'v'))
반환(return)문
'2021-1 > Expert' 카테고리의 다른 글
| LDA | 오류해결 및 시각화 (0) | 2021.10.25 |
|---|---|
| LDA | Delete Korean Stopword (0) | 2021.10.23 |
| 쥬피터 노트북 | LDA 실습 (0) | 2021.10.14 |
| LDA | 실습하기 (0) | 2021.10.14 |
| LDA | 실습하기 (0) | 2021.10.13 |


