지수팀 LDA 코드 구현 설명
주피터 노트북
LDA 알고리즘
import pandas as pd

이 코드가 무엇을 의미하는지 모를 때에는 print( ) 를 사용해서 로그를 찍어본다
- data_text = data[['title']] : 데이터 속에 컬럼이 year 과 title 이 있는데 우리에게 필요한 것은 타이틀 데이터만 이어서 데이타 텍스트에서 타이틀만 변수를 지정해준다.
- data_text['index'] 에서 인덱스가 없기 때문에 count 하기 쉽게 하기 위해서 인덱스를 달아준다
- data_text 가 길기 때문에 documents 로 변수를 지정해준다.
- len(documents) 는 2100 줄이다
- 시범삼아 documents[:5] 를 인덱스 5번까지 출력해본다

- nltk : 자연어처리 툴키트
- gensim : Topic Modeling
- stemmer SnowballStemmer("English") : 지정언어를 적어준다( 한글은 없고 프렌치, 네덜란드어 등 지원되는 언어가 더 있다)

* np.random.seed(2018) : seed 는 난수를 예측가능하도록 만든다. 난수이지만 동일한 셋트의 난수가 출력되게 된다/
<-> np.random.rand( ) : 매번 서로 다른 난수가 출력된다.
- lemmatize_stemming(text)
- stemming 어간 추출, Lemamatization 표제어 추출 을 의미한다/ 하나의 단어로 일반화시켜서 문서 내의 단어 수를 줄이겠다는 것, BoW(Bag of Words) 표현을 사용하는 자연어 처리 문제에서 주로 사용된다.
- 표제어 : 기본 사전형 단어 정도의 의미를 갖는다. 표제어 추출은 단어들로부터 표제어를 찾아가는 과정이다/ 예) am, are, is => be
- 어간 : stem
- 접사 : affix
- cat(어간) - -s(접사)
- 그래서 코드를 돌리니깐 -ization , -s 등의 접사(affix) 들이 다 삭제되었구나! 그것이 stemming 을 통해서 이루어 진 것이었다.
- NLTK 에서는 표제어 추출을 위한 도구인 WordNetLemmatizer 를 지원해서 저것을 사용해주었구나.
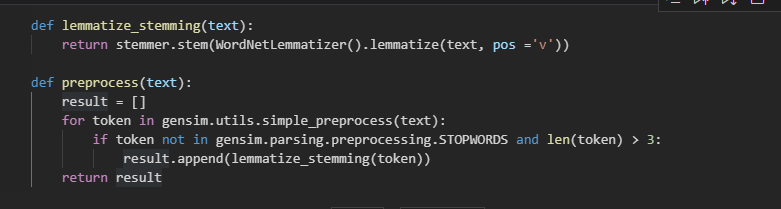
- lemmatizer 표제어 추출기가 본래 단어의 품사 정보를 알아야만 정확한 결과를 얻을 수 있다고 해서 pos='v' 를 설정해주었구나
-
Stemming 어간 추출 Lemmatization 표제어 추출 am -> am am -> be the going -> the go the going -> the going having -> hav having -> have - stemmer.stem(WordNetLemmatizer().lemmaize(text, pos = 'v')
PREPROCESS(전처리)
불필요한 데이터 delete 처리
예) -ated, -ous(접미사), -es, -s(복수형) 삭제처리
create new modeling
Dictionary
list를 for 문으로 해서 해도 되지만,, 후에 dfs 를 사용할 것이기에 딕셔너리 형태로 만들어준다.
dfs in graph : easier 한 도구이다
'2021-1 > Expert' 카테고리의 다른 글
| LDA | 실습하기 (0) | 2021.10.14 |
|---|---|
| LDA | 실습하기 (0) | 2021.10.13 |
| LDA | DTM, TF-IDF (0) | 2021.10.13 |
| LDA | 실습하기 (0) | 2021.10.11 |
| Vue.js | 뷰 기본 및 다운로드 방법 (0) | 2021.10.04 |



